{var%20f='http://v.t.sina.com.cn/share/share.php?appkey=1515056452',u=z||d.location,p=['&url=',e(u),'&title=',e(t||d.title),'&source=',e(r),'&sourceUrl=',e(l),'&content=',c||'gb2312','&pic=',e(p||'')].join('');function%20a(){if(!window.open([f,p].join(''),'mb',['toolbar=0,status=0,resizable=1,width=440,height=430,left=',(s.width-440)/2,',top=',(s.height-430)/2].join('')))u.href=[f,p].join('');};if(/Firefox/.test(navigator.userAgent))setTimeout(a,0);else%20a();})(screen,document,encodeURIComponent,'','','https://www.xiaopingtou.cn//data/attach/topic/topicKPo7gB.jpg', '推荐 TigerShi 的文章《DSP 中的基础算法和模型的详细解析》','https://www.xiaopingtou.cn/article-75687.html','页面编码gb2312|utf-8默认gb2312'));){kind=link}
(转载请保留原文链接 http://www.techinads.com/archives/41
authored by 江申_Johnson)
美国有一家很优秀的 DSP 公司——M6D(m6d.com),这个公司只是个 startup 公司,却已经在 KDD 之类的顶级会议发表了 7-8 篇优秀的文章。最近我研究了一下他们的 DSP 算法,和大家分享一下我的理解,希望以一个实例让大家对
DSP 中的基础算法和模型有一个初步的了解。写得不对的地方,还请大家及时指正。
这篇文章假设大家对 DSP 及 RTB 生态圈各种三个字母缩写的概念有初步的理解。
之后,每个compaign就会根据每个用户通过audience selection model预估的转化概率p(c|u)选出目标用户,m6d的经验数据是不超过百分之一的用户会成为某个compaign的目标用户。然后这些目标用户会根据不同的转化概率阈值划分到不同的segments中。例如p(c|u)>0.01放到一个segment中,0.01>= p(c|u) > 0.001放到另外一个segment中。论文中没有说到一个用户是否可以放到两个或以上的segment中,但我觉得应该是可以的。每个compaign有大约10到50个segments左右。划分segments的作用一是方便账户管理员对每个segment设置基础出价,另外在后面介绍的bidding算法中将属于同一个segment的用户做无差别对待,相当于同属一个类,可以缓解某些用户数据稀疏的问题,后面会详细介绍。 以上就是m6d的audience selection算法,值得注意的是,上述步骤是offline的,也即是预处理的,在exchange的请求到来前就已经对每个compaign都算好了。有的地方把根据广告主的一些少量已知转化用户找到更多潜在用户的模型叫做Look-alike Model, 我理解这里的audience selection model也应该算是look-alike model。 Bidding: 当exchange发送请求时,DSP会接受到当前用户的cookie和一些最基本的用户信息,以及当前广告位的信息。DSP则需要找到这个用户所属的所有segments,而这些segments可能会对应多个compaign。那么应该出哪个compaign的广告呢?这里有一个内部竞价的过程。 m6d是这么做的,首先要把一些不合适出广告的compaign根据规则过滤掉。主要的规则有,如果一个用户之前已经被展现了这个compaign的广告数达到一定的个数了,那么就不要再浪费广告费了(这个次数限制通常叫frequency cap)。另外一个主要规则是,如果一个compaign已经达到了它的每日,或者每周,或者每月预算限制了,那么也不再为它投放广告了。对于剩下的compaign候选,DSP会对他们都根据算法计算出最合适的出价,然后简单地选取出价最高的那个(出价反映了当前用户对该compaign的价值)。细心的朋友会发现这里是一个贪心的算法,有优化的空间,这个我们最后一起来总结。 下面介绍下对于某一个compaign, 如何计算对当前展现机会的出价。 前面的audience selection部分,我们已经对每个用户划分了segments,然后账户管理员又对每个segment给出了基础出价(base price),当时这个出价考虑的是这个用户和这个compaign的适合程度,并没有考虑当前广告位是否适合这个compaign投广告,是否适合这个用户。因此m6d的算法,以基础出价为基准,根据当前广告位计算出一个调整因子 Φ ,最后的出价就是 baseprice∗Φ 。因此我们全部的工作就是要计算这个 Φ 。 如果上过刘鹏老师的计算广告学课的同学肯定会知道,在广义二阶竞价模型里,排序是应该按照 ecpm=转化率*转化价值 来排序的。ecpm可以认为是一个展现的价值,它等于一个转化的价值*一个展现变为一个转化的概率。其实我想说的就是,对于同一个compaign来说,如果我们知道一个展现的转化率是另外一个展现的2倍,那么后面那个展现的出价应该是前面那个展现的出价的2倍。 按照上面的逻辑,既然我们为segments出了一个平均价格base price,当仅当一个展现的转化率是这个segments中用户的平均转化率的 Φ 倍,我们应该为这个展现出 baseprice∗Φ 的出价。所以 Φ=p(c|u,i)/Ej[p(c|u,j)] 其中,u指的是用户,i是当前的广告位(inventory),c指的是转化。分母计算的是在所有广告位(用j指代)上的平均转化率。这个分母要计算起来很复杂,我们要遍历所有的广告位(inventory)。但我们知道: p(c|u)=Ej[p(c|u,j)]=∑jp(c|u,j)p(j) 因此有 Φ=p(c|u,i)p(c|u) 所以m6d的bidding算法的最核心部分,就是为每个compaign都建立两个模型来分别预估p(c|u,i)和p(c|u)。考虑到每个compaign的转化数据很少,这2个模型的训练数据很少,要训练这两个模型太难了。因此m6d将同一个segment中的用户不做区分,从而可以把上式变为 Φ=p(c|s,i)p(c|s) 其中,s是segment。这样就只需要训练p(c|s,i)和p(c|s)。因为s的个数远小于u的个数,这2个模型的特征空间显著变小了,模型更容易得到更好的结果。事实上,m6d也对i的部分做了类似的trick,它把类似的广告位聚合到一起,给予一个相同的inventory id。目的和把u变为s是类似的。m6d的inventories的规模是5000个左右,每个compaign的segment的个数是10到50个左右。 以上就是m6d对bidding的建模过程了,剩下的工作就是如何训练得到这两个模型。 p(c|s,i)模型: 要得到这个模型的训练数据,还有一个冷启动的过程。必须事先对这些segments在这些inventories上投放,然后把那些最终带来转化的展现标记为正例,没有最终带来转化的展现标记为负例。m6d认为一次转化是由之前7天内该用户见到的最后一次展现带来的。这个模型的特征只有两类,一类就是segment id, 另外一类就是inventory id。也就是说,每一个样本只有两个非0的特征,一个是segment id对应的那个特征,另外一个是inventory id对应的那个特征。m6d没有组合segment和inventory特征,这样做的结果是:不管对于哪个segment,某个特定的inventory对最后预估值的贡献都是一样的。这个假设可以认为在大多数情况下是合理的。而且如果真要把这些组合特征加入模型,特征空间一下子又大了不少,对于少得可怜的训练数据来说,很容易就过拟合了。 p(c|s)模型:和p(c|s,i)模型基本一样,区别就是特征只有segment id。 这两个模型的正例比例都非常低,因此进行了采样(sampling)和修正(recalibration)。这是一种很常见的处理方式,不了解的朋友可以Google这篇文章:《Logistic regression in rare events》。 考虑了广告位(inventory)和不考虑广告位对转化率的预估有多大的影响呢?以下的图展示了区别:
考虑广告位信息后,AUC提升了0.0346,还是非常明显的。这个Lift也是一种评估指标,后面会详细解释。这里可以看到Lift指标也明显提升了。 具体看个例子。对于一个hotel广告主的一个compaign,不同的广告位预估出来的 Φ 值也很不相同,旅游类的预估值最高,社会媒体的最低。说明这个模型还是有一定区分度的。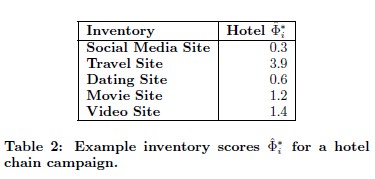
评估: 1. 模型评估 通常我们用AUC来评估模型的排序能力,但是AUC有一个问题是它无差别地考察了一个列表中所有位置的排序合理性,而对于我们的audience selection模型,转化率预估模型,我们更看重是否把最靠谱的拍在了前面,换句话说,是更看重这个列表中前面位置的排序合理性。因此m6d用了Lift指标。Lift@5% 指标衡量了在前5%的结果中,正例的比例比在随机情况下正例出现的比例高了多少。具体的Lift定义可以看:http://en.wikipedia.org/wiki/Lift_(data_mining) 2. 业务目标评估 对于DSP的投放效果,m6d主要会看两个业务指标,一个是转化率(PVSVR), 即转化数除以展现数(即CTR*CVR);另外一个是CPA, 即获得每一个转化,平均花了多少钱。 m6d的广告主大多喜欢按CPM方式购买展现,找n家DSP来同时投放,给一样的CPM,然后看谁的转化率高。因此转化率是DSP赖以生存的指标之一。 转化率是和价格无关的,而如果一家DSP虽然转化率低10%,但是每个展现的价格(cpm)比别人低50%,那么对于广告主来说,还是会选择它的。因为它的CPA更低了,即获取一个转化,广告主需要付出的成本更低了。 所以,DSP的转化率是和利润挂钩的,要么把技术做得很好提高转化率,这样在保持CPA不变的情况下,向广告主收取更高的CPM,从而赚更多的钱。否则就只能比别人卖得更便宜了,甚至亏本了。当然,聪明的DSP会在早期先砸VC的钱亏本吸引广告主来投放,投放是可以累积数据的,有了数据下次就可以把转化率做得更好,从而再把钱赚回来。 也有广告主是按每个点击付费的(CPC),有的广告主是给一笔固定的投放预算,但其实最后都是类似的,广告主最终会去换算成CPA来进行比较。(只重视展现量的广告主除外)
[1] Bid Optimizing and Inventory Scoring in Targeted Online Advertising [2] Design Principles of Massive, Robust Prediction Systems [3] Bid Landscape forecasting in Online Ad Exchange Marketplance [3] 师徒网刘鹏老师《计算广告学》课件:http://www.sheetoo.com/app/course/overview?course_id=200
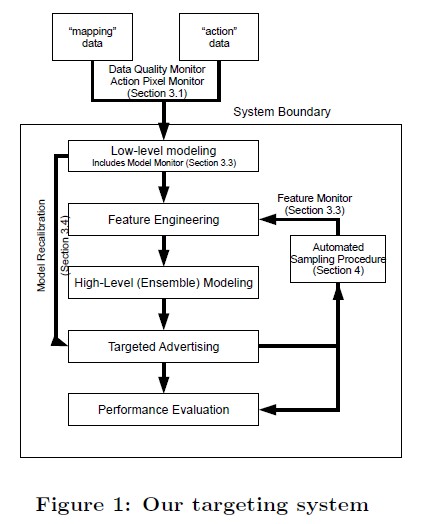
整体流程
首先,我们先来看一下 M6D 的 DSP 工作的整个流程:- 追踪用户行为:DSP公司通常会在广告主的网站上埋点(即放上一个1×1的不可见像素),这样当互联网用户第一次访问广告主的网站时,就会得到DSP公司的一个cookie,这样DSP公司就可以追踪到这个网民的在广告主网站上的行为了(这些数据也叫action data)。DSP公司还会和第三方的网站合作(例如:新浪,腾讯),在他们的网站上也埋点,或者向DMP购买网民行为数据,这样就可以追踪到网民在这些网站上的行为了(这些数据也叫mapping data)。这里值得一提的是,DSP公司对某一个用户记录的cookie和第三方网站或DMP或exchange记录的cookie是不一样的,这里需要一个叫Cookie Mapping的过程,这不是本文重点,以下假设DSP已经做好了Cookie Mapping,每个用户有一个唯一的id标识。
- 受众选择(audience selection): m6d对每一个Compaign(即每一个广告主的每个推广活动), 训练一个audience selection model, 该模型以在广告主的网站上发生转化行为(转化行为可以是注册成为用户,点击某个特定页面,购买产品。每个广告主对转化的定义不一样)的用户为正例,没有发生转化行为的用户为负例(是的,正负例很不均匀,通常要做采样和结果修正)。得到模型后,对所有的用户预估对这个compaign的转化概率p(c | u),即该用户u有多大的概率会在广告主的网站上发生转化行为(c表示conversion),去掉大多数转化概率非常小的用户,将目标用户根据转化概率高低分到不同的segments中。这样我们对每个compaign就找到了很多的目标用户,而且这些用户根据他们的质量高低,被分别放在不同的segments中。
- 通知exchange:DSP将这些目标用户的cookie告诉exchange,这样当有这些cookie的请求来的时候,exchange才会来向DSP的服务器发送请求。
- Segment管理:通常DSP公司会有账户管理员(运营人员),他们人工来对每个compaign做一些设定。他们根据每个compaign所属的行业特点,经济状况,决定开启哪些segments,关掉哪些segments。例如:对没钱的小公司的compaign, 那些用户转化概率小一些的segment就不要投广告了。他们还需要对每个segment设定一个基础出价(base price)。账户管理员可以拿到每个segment的平均预估转化率,来辅助他们设定基础出价。这一步也是人工影响投放策略最主要的地方。
- 进行实时竞价:当exchange把请求发过来的时候,DSP会拿到以下信息:当前广告位的信息,当前用户的cookie和基本信息。DSP需要在100ms内,根据对当前用户的理解,并且考虑当前广告位,根据自己的bidding算法,来决定是否要买这次展现,投放哪个compaign的广告,出价是多少(bidding),并向exchange返回出价信息?如果超过时间DSP没有响应,则exchange默认DSP放弃这次竞价。
- 展现广告:如果赢得了展现机会,则DSP返回创意,用户就会在该广告位看到该创意。
- 追踪转化:因为DSP在广告主的网站上埋了点,就能知道用户是否在这次展现之后进行了转化行为。根据这些数据统计转化率,每个转化平均成本等指标,汇总成报告给广告主。
核心算法
第2步(Audience Selection)和第5步(Bidding)是最核心的两步,其中audience selection是离线计算过程,因为可以在exchange发送请求前离线慢慢算好,而bidding的过程需要在100ms内在线快速算好。下面分开介绍这两步中的算法和模型,最后介绍如何对算法效果进行评估。 Audicence Selection: m6d的Audience Selection算法需要对每个compaign都训练以下两个模型(对每个compaign独立训练模型是因为广告主隐私保护,从一个广告主网站上采集的数据不能用来优化另外一个广告主的模型,例如不能利用京东上访问过电视购买页面的用户数据,来给苏宁电器优化模型,被京东知道了,他们的生意你以后就没得做了。另外一个原因是分每个compaign单独训练模型在训练数据充足的时候可能有更优的效果。当然隐私的原因是主要原因):- Low-level Model: 这个模型的作用是做初选。所有在该compaign对应的广告主网站上发生转化行为的用户作为正例,其他的用户作为负例(即利用action data)。该模型的特征只有一类,就是用户历史访问过的URL(即利用mapping data)。也就是说,所有可能的URL数就是特征空间的维数,如果用户访问过某个URL,那么这个URL对应的那一维特征的取值就是1,否则就是0. 显而易见,这样会导致特征空间维数太大,所以要做一个最基本的特征选择:去掉那些覆盖用户的转化总数小于某个固定的转化数阈值(比如5)的特征(具体做的时候可以用展现数过滤,阈值设为 转化数阈值/平均转化率)。这样会显著减少特征的数量。即使大幅减少了特征,但数目还是很多,所以这个模型m6d不意外地用了线性模型。
- High-level Model: 这个模型的作用是细选。模型的样本和Low-level Model一样,特征就不限于用户访问过的URL了,可以是这个用户的各种挖掘出来的属性标签,包括可解释的分类标签,不可解释的聚类id, topic id,与广告主网站的关联特征等。这里也就是用户属性标签(user profile)起作用最重要的地方了,给用户打标签的技术是很多广告公司的基本功,这里就不着重介绍了。有意思的是,m6d还用了Low-level Model的输出值作为特征之一。这个模型m6d还是选择了线性模型,但因为这个模型要预测的样本数比较少了,可以做一些复杂的计算。m6d选择了一个非线性模型(Generalized additive model with smoothing splines)对结果进行修正。
之后,每个compaign就会根据每个用户通过audience selection model预估的转化概率p(c|u)选出目标用户,m6d的经验数据是不超过百分之一的用户会成为某个compaign的目标用户。然后这些目标用户会根据不同的转化概率阈值划分到不同的segments中。例如p(c|u)>0.01放到一个segment中,0.01>= p(c|u) > 0.001放到另外一个segment中。论文中没有说到一个用户是否可以放到两个或以上的segment中,但我觉得应该是可以的。每个compaign有大约10到50个segments左右。划分segments的作用一是方便账户管理员对每个segment设置基础出价,另外在后面介绍的bidding算法中将属于同一个segment的用户做无差别对待,相当于同属一个类,可以缓解某些用户数据稀疏的问题,后面会详细介绍。 以上就是m6d的audience selection算法,值得注意的是,上述步骤是offline的,也即是预处理的,在exchange的请求到来前就已经对每个compaign都算好了。有的地方把根据广告主的一些少量已知转化用户找到更多潜在用户的模型叫做Look-alike Model, 我理解这里的audience selection model也应该算是look-alike model。 Bidding: 当exchange发送请求时,DSP会接受到当前用户的cookie和一些最基本的用户信息,以及当前广告位的信息。DSP则需要找到这个用户所属的所有segments,而这些segments可能会对应多个compaign。那么应该出哪个compaign的广告呢?这里有一个内部竞价的过程。 m6d是这么做的,首先要把一些不合适出广告的compaign根据规则过滤掉。主要的规则有,如果一个用户之前已经被展现了这个compaign的广告数达到一定的个数了,那么就不要再浪费广告费了(这个次数限制通常叫frequency cap)。另外一个主要规则是,如果一个compaign已经达到了它的每日,或者每周,或者每月预算限制了,那么也不再为它投放广告了。对于剩下的compaign候选,DSP会对他们都根据算法计算出最合适的出价,然后简单地选取出价最高的那个(出价反映了当前用户对该compaign的价值)。细心的朋友会发现这里是一个贪心的算法,有优化的空间,这个我们最后一起来总结。 下面介绍下对于某一个compaign, 如何计算对当前展现机会的出价。 前面的audience selection部分,我们已经对每个用户划分了segments,然后账户管理员又对每个segment给出了基础出价(base price),当时这个出价考虑的是这个用户和这个compaign的适合程度,并没有考虑当前广告位是否适合这个compaign投广告,是否适合这个用户。因此m6d的算法,以基础出价为基准,根据当前广告位计算出一个调整因子 Φ ,最后的出价就是 baseprice∗Φ 。因此我们全部的工作就是要计算这个 Φ 。 如果上过刘鹏老师的计算广告学课的同学肯定会知道,在广义二阶竞价模型里,排序是应该按照 ecpm=转化率*转化价值 来排序的。ecpm可以认为是一个展现的价值,它等于一个转化的价值*一个展现变为一个转化的概率。其实我想说的就是,对于同一个compaign来说,如果我们知道一个展现的转化率是另外一个展现的2倍,那么后面那个展现的出价应该是前面那个展现的出价的2倍。 按照上面的逻辑,既然我们为segments出了一个平均价格base price,当仅当一个展现的转化率是这个segments中用户的平均转化率的 Φ 倍,我们应该为这个展现出 baseprice∗Φ 的出价。所以 Φ=p(c|u,i)/Ej[p(c|u,j)] 其中,u指的是用户,i是当前的广告位(inventory),c指的是转化。分母计算的是在所有广告位(用j指代)上的平均转化率。这个分母要计算起来很复杂,我们要遍历所有的广告位(inventory)。但我们知道: p(c|u)=Ej[p(c|u,j)]=∑jp(c|u,j)p(j) 因此有 Φ=p(c|u,i)p(c|u) 所以m6d的bidding算法的最核心部分,就是为每个compaign都建立两个模型来分别预估p(c|u,i)和p(c|u)。考虑到每个compaign的转化数据很少,这2个模型的训练数据很少,要训练这两个模型太难了。因此m6d将同一个segment中的用户不做区分,从而可以把上式变为 Φ=p(c|s,i)p(c|s) 其中,s是segment。这样就只需要训练p(c|s,i)和p(c|s)。因为s的个数远小于u的个数,这2个模型的特征空间显著变小了,模型更容易得到更好的结果。事实上,m6d也对i的部分做了类似的trick,它把类似的广告位聚合到一起,给予一个相同的inventory id。目的和把u变为s是类似的。m6d的inventories的规模是5000个左右,每个compaign的segment的个数是10到50个左右。 以上就是m6d对bidding的建模过程了,剩下的工作就是如何训练得到这两个模型。 p(c|s,i)模型: 要得到这个模型的训练数据,还有一个冷启动的过程。必须事先对这些segments在这些inventories上投放,然后把那些最终带来转化的展现标记为正例,没有最终带来转化的展现标记为负例。m6d认为一次转化是由之前7天内该用户见到的最后一次展现带来的。这个模型的特征只有两类,一类就是segment id, 另外一类就是inventory id。也就是说,每一个样本只有两个非0的特征,一个是segment id对应的那个特征,另外一个是inventory id对应的那个特征。m6d没有组合segment和inventory特征,这样做的结果是:不管对于哪个segment,某个特定的inventory对最后预估值的贡献都是一样的。这个假设可以认为在大多数情况下是合理的。而且如果真要把这些组合特征加入模型,特征空间一下子又大了不少,对于少得可怜的训练数据来说,很容易就过拟合了。 p(c|s)模型:和p(c|s,i)模型基本一样,区别就是特征只有segment id。 这两个模型的正例比例都非常低,因此进行了采样(sampling)和修正(recalibration)。这是一种很常见的处理方式,不了解的朋友可以Google这篇文章:《Logistic regression in rare events》。 考虑了广告位(inventory)和不考虑广告位对转化率的预估有多大的影响呢?以下的图展示了区别:
考虑广告位信息后,AUC提升了0.0346,还是非常明显的。这个Lift也是一种评估指标,后面会详细解释。这里可以看到Lift指标也明显提升了。 具体看个例子。对于一个hotel广告主的一个compaign,不同的广告位预估出来的 Φ 值也很不相同,旅游类的预估值最高,社会媒体的最低。说明这个模型还是有一定区分度的。
评估: 1. 模型评估 通常我们用AUC来评估模型的排序能力,但是AUC有一个问题是它无差别地考察了一个列表中所有位置的排序合理性,而对于我们的audience selection模型,转化率预估模型,我们更看重是否把最靠谱的拍在了前面,换句话说,是更看重这个列表中前面位置的排序合理性。因此m6d用了Lift指标。Lift@5% 指标衡量了在前5%的结果中,正例的比例比在随机情况下正例出现的比例高了多少。具体的Lift定义可以看:http://en.wikipedia.org/wiki/Lift_(data_mining) 2. 业务目标评估 对于DSP的投放效果,m6d主要会看两个业务指标,一个是转化率(PVSVR), 即转化数除以展现数(即CTR*CVR);另外一个是CPA, 即获得每一个转化,平均花了多少钱。 m6d的广告主大多喜欢按CPM方式购买展现,找n家DSP来同时投放,给一样的CPM,然后看谁的转化率高。因此转化率是DSP赖以生存的指标之一。 转化率是和价格无关的,而如果一家DSP虽然转化率低10%,但是每个展现的价格(cpm)比别人低50%,那么对于广告主来说,还是会选择它的。因为它的CPA更低了,即获取一个转化,广告主需要付出的成本更低了。 所以,DSP的转化率是和利润挂钩的,要么把技术做得很好提高转化率,这样在保持CPA不变的情况下,向广告主收取更高的CPM,从而赚更多的钱。否则就只能比别人卖得更便宜了,甚至亏本了。当然,聪明的DSP会在早期先砸VC的钱亏本吸引广告主来投放,投放是可以累积数据的,有了数据下次就可以把转化率做得更好,从而再把钱赚回来。 也有广告主是按每个点击付费的(CPC),有的广告主是给一笔固定的投放预算,但其实最后都是类似的,广告主最终会去换算成CPA来进行比较。(只重视展现量的广告主除外)
延伸讨论
上面的篇幅研究了m6d的DSP的算法和模型,我觉得有些地方可能可以有不同的做法(不一定更优),写出来和大家探讨一下: 1. bidding中的转化率模型 前面的audience selection model (look-alike model)对每个compaign分别建模还有可能是因为在每个compaign训练数据充分的情况下可能取得更好的预估效果。而后面的两个转化率模型将每个compaign分别建模就一定是因为privacy的原因了,因为每个compaign的这2个模型的训练数据太少了,而且m6d用的是转化作为正样本,还不是点击作为正样本,那正例就更少了。所以m6d不得不将u替换成s来建模,将相似广告位(inventory)用同一个inventory id表示,来拼命减少特征空间,在少得可怜的数据下,牺牲bias来换取低variance从而抑制过拟合,提高模型泛化能力。 如果没有那么高的privacy要求,是可以对所有compaign的数据一起来训练一个的统一模型的。事实上,我了解到国内大多数公司都是这么做的。再考虑到国内的广告主对点击也比较看重,所以更通常一点的建模方式是:对所有compaign建立一个CTR模型(预估点击率=点击/展现)p(click|u,i,a),这里的a指一个compaign,和一个CVR模型(转化/点击)p(conversion|u,i,a)。这样训练数据就更丰富了,也可以直接对每个用户来预估,不需要对整个segment来预估。当然,这样的一个结果是在某个广告主网站上的点击和转化数据,可能对另外一个广告主的点击和转化预估起到正向的作用。在不明显有偏向性的算法设计下,可能会使大多数广告主的预估都有一些提升(尤其是那些数据很少的小广告主)。 2. 内部竞价机制 m6d的算法在内部竞价时是选择bid最高的compaign。这是一种明显的贪心算法,在考虑到每个广告主有预算限制的情况下,不一定是最优的。举个例子,广告主A要的用户是对乔丹感兴趣的用户,因为他是卖乔丹的运动鞋的,但是他们是小公司,出不起太高的价来打广告;广告主B是的要的用户是对篮球感兴趣的用户。这个时候来了一个经常上新浪体育乔丹个人页面的用户,广告主A经过bidding算法后出了封顶价3块钱,广告主B很有钱,基础出价就是4块钱,bidding算法调整后比如是4.5块。那么广告主B的广告会在内部胜出。当事实上对篮球感兴趣的用户很多,广告主B完全可以在其他流量上买到足够多的展现而达到当日预算限额,而对乔丹感兴趣的用户的展现可能1天就2,3个,广告主A这次买不到,可能当日预算一点都花不出去。 这个优化在系统进化早期可能效果不明显,当平台成熟了,量上去了,可能会有作用。 3. 考虑外部竞争 m6d的出价算法是基于价值的出价算法,没有考虑竞争对手出价。也就是说,我觉得这个展现值多少钱,我就出多少钱,不管其他人的出价是多少。这样有可能会出现出价严重偏离市场价的情况,就好比在北京买房子,郊区一个老破房子,你可能觉得只值2000块一平,但是市场上都已经出到20000了,不调整出价根本就买不到房子了。 因此专门有一个技术叫Bid Landscape Forecasting, 用来预测其他竞争对手的出价情况,实际应用中它要预测的是bid与能购买到流量的一个函数关系,也就是出多少钱能买到多少流量的这么一个曲线,从而根据自己的需求来调整自己的出价。详细可以Google这篇文章《Bid Landscape Forecasting in Online Ad Exchange Marketplace》。 M6d的算法里有一部分是账户管理员对segment打一个base price,我相信这个base price应该会考虑到市场竞争的情况。 4. 流量预测、预算控制 对于广告主来说,关心的是两个东西,一个是质,一个是量。质的意思是投放的广告要投在那些可能对这个广告感兴趣的人身上,量的意思是,得找到并投放足够多的这样的广告。宝洁公司对于那种每天只能覆盖1,2个人的广告compaign是不会感兴趣的,即使这2个人的转化率都是100%。 但是因为RTB是要实时决定你是否去竞争这个展现,DSP需要对后续可能出现的展现有一个预判。打个比方来说,假设你去相亲,有多少女生会来你是不知道的,但是你总共有约会5个女朋友的机会。接下来每个女生依次和你见面,你要马上决定是否和她约会。这个时候如果你对女生的整体质量有一个估计,或者对总共有多少女生会来有一个估计,就会做出更明智的选择。 这个其实也是Bid Landscape Forecasting的一部分,因为它是要预测bid与能购买到流量的一个函数关系。能购买的流量一方面和竞争有关,另外一部分和流量的质量和数目有关系。 5. 点击率、转化率 m6d是直接对转化建模的,而不是分为点击率和点击后的转化率来建模的(有一些compaign,对广告主页面的点击就被认为是转化,对这些compaign两种方式没有区别)。点击数据对于m6d来说就没有作用了。如果有很多点击数据,分开建模可能会有更好的效果,因为能把点击数据利用上了。 6. 品友互动RTB比赛 通过参加品友的RTB比赛,对DSP的了解也加深了一层,也积累了一点点实战经验。把新的收获都分享在Data Science Workshop @ Beijing 的Slides里了,地址如下: http://pan.baidu.com/share/link?shareid=322913515&uk=3138366223 Slides中的主要内容有:- RTB模式下各个角 {MOD}与Ad Network模式下的差异。
- DSP的三种主要Audience Selection方法:基于标签,基于重定向,基于Look-alike Model。
- DSP的基础出价算法(分别介绍了M6D的,品友比赛中采用的)。
- DSP中的CTR预估与传统CTR预估的三个差异点。
- 如何在线根据反馈实时调整出价模型?
参考文献
[1] Bid Optimizing and Inventory Scoring in Targeted Online Advertising [2] Design Principles of Massive, Robust Prediction Systems [3] Bid Landscape forecasting in Online Ad Exchange Marketplance [3] 师徒网刘鹏老师《计算广告学》课件:http://www.sheetoo.com/app/course/overview?course_id=200